
CSDN论坛上有关Google Trend的讨论帖子数量颇多。但系统性地整理和大规模抓取存储这些内容的帖子却相对较少。今天,我们参考了前辈们的经验,目标是构建一个流程化的词频抓取与存储系统。
必备梯子很关键
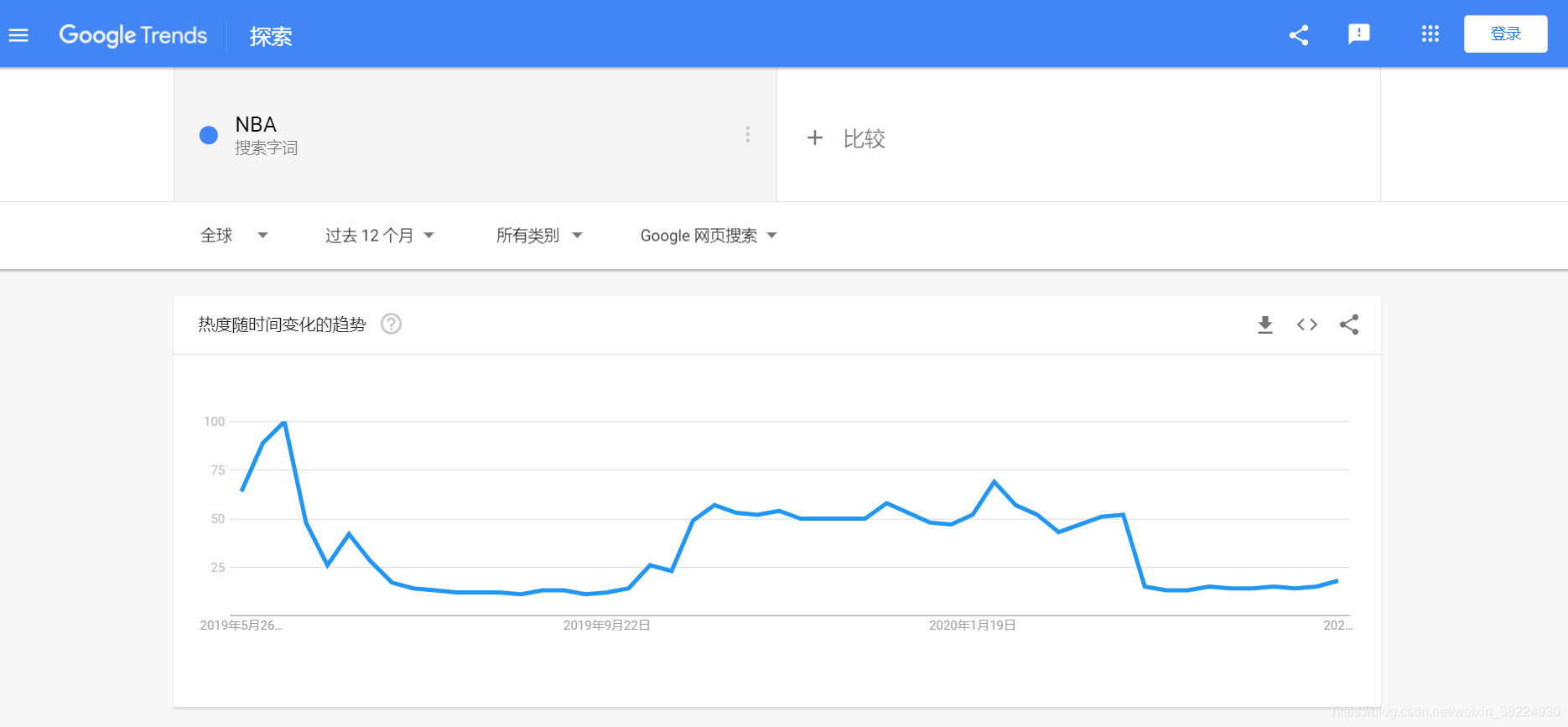
捕捉URL参数
输入关键词后,需关注URL参数的配置与顺序。这一过程涉及众多技巧,每个参数都蕴含着特定的意义与功能。就如同握着一把钥匙,需明确它对应哪扇门。需细致观察参数间的联系,这将为后续分析打下坚实基础。
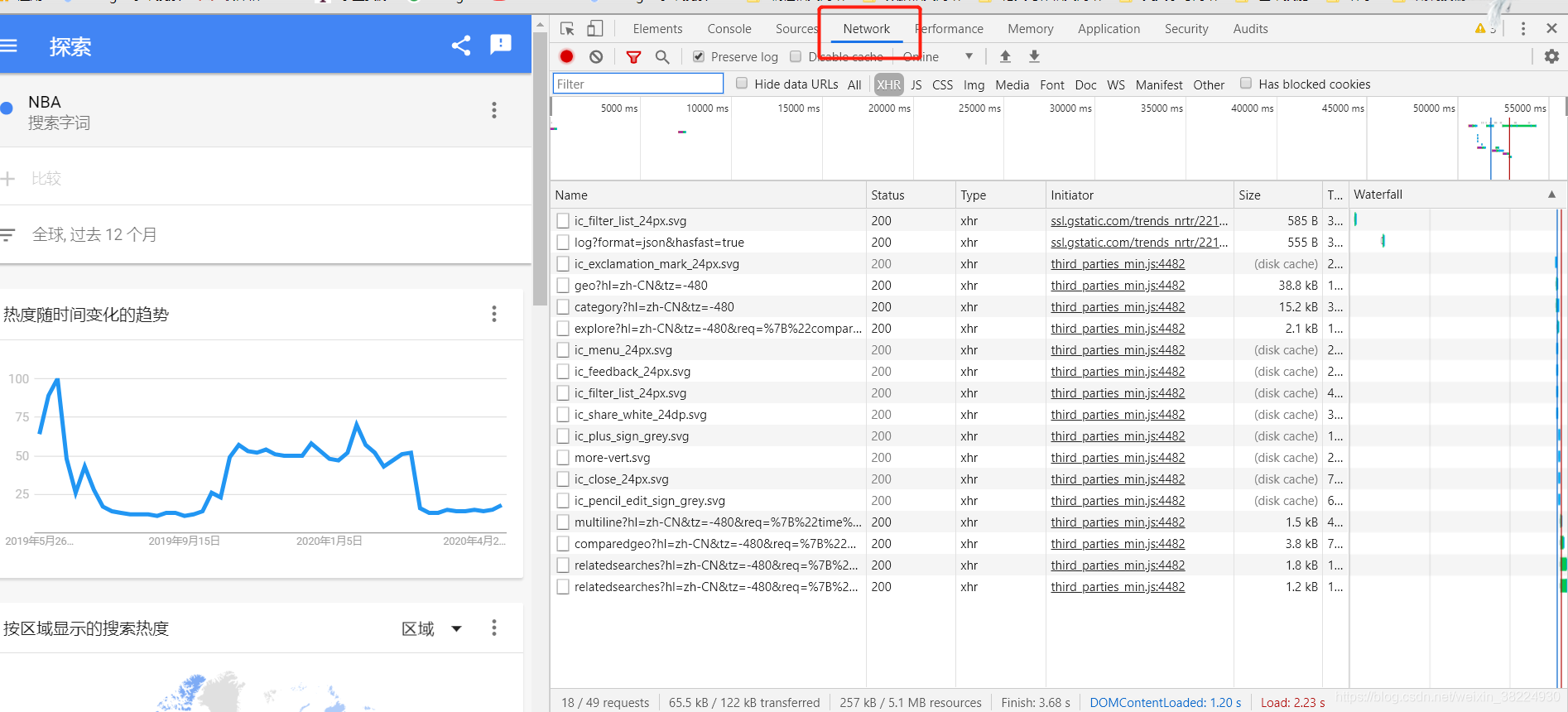
查找网络元素
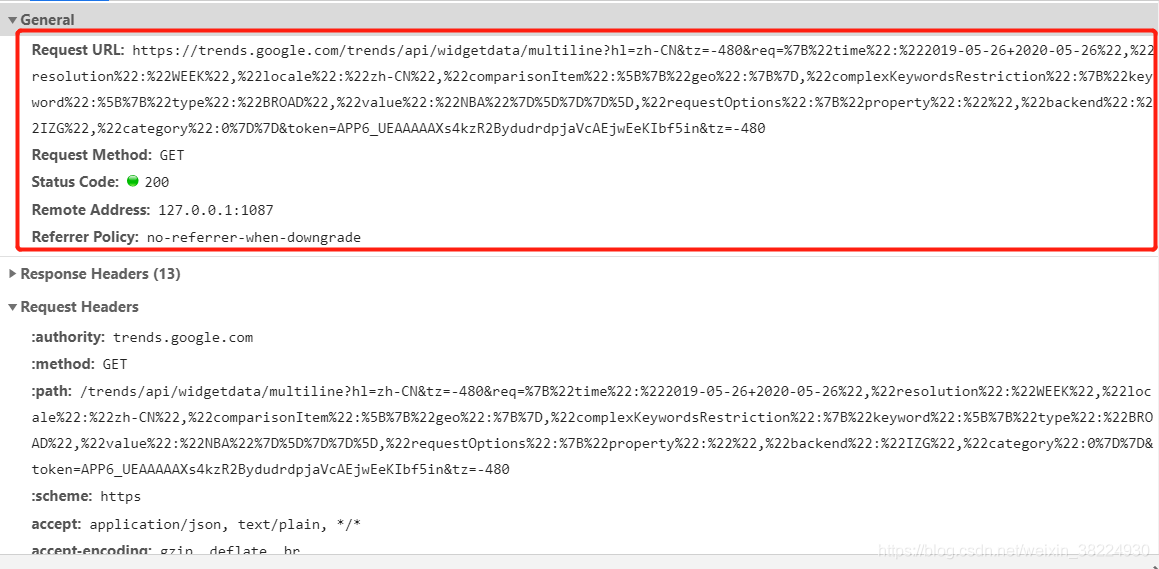
启动Chrome浏览器,用鼠标点击右侧键,选择“检查”功能。接着,在选项中找到“网络”部分。开始时页面可能呈现空白,不必紧张,轻按F5键刷新页面,网页的网络信息便会显现。这里藏有众多宝贵信息,犹如地底宝藏,等待你去探寻。每一项内容都可能与你所需的数据紧密相连。
分析URL参数
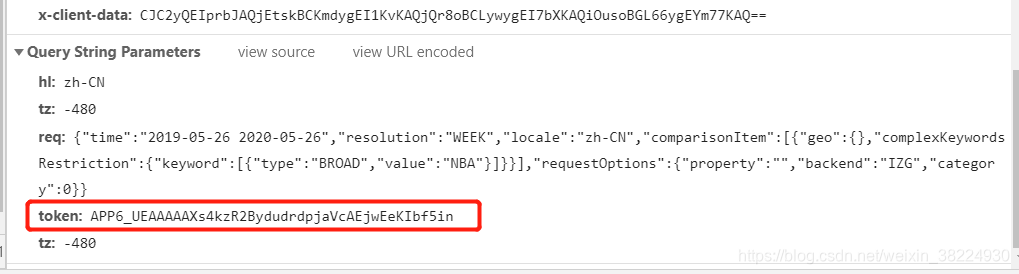
查看目标网站的回应,或是通过预览功能来审视信息的多种呈现方式。网站的关键参数包括ht、tz、req和token四个。不论网页如何变化,ht和tz这两个参数始终保持稳定。至于req参数,它会根据我们的具体需求生成,这一点至关重要,因为它直接影响到我们能否准确获取所需的信息。
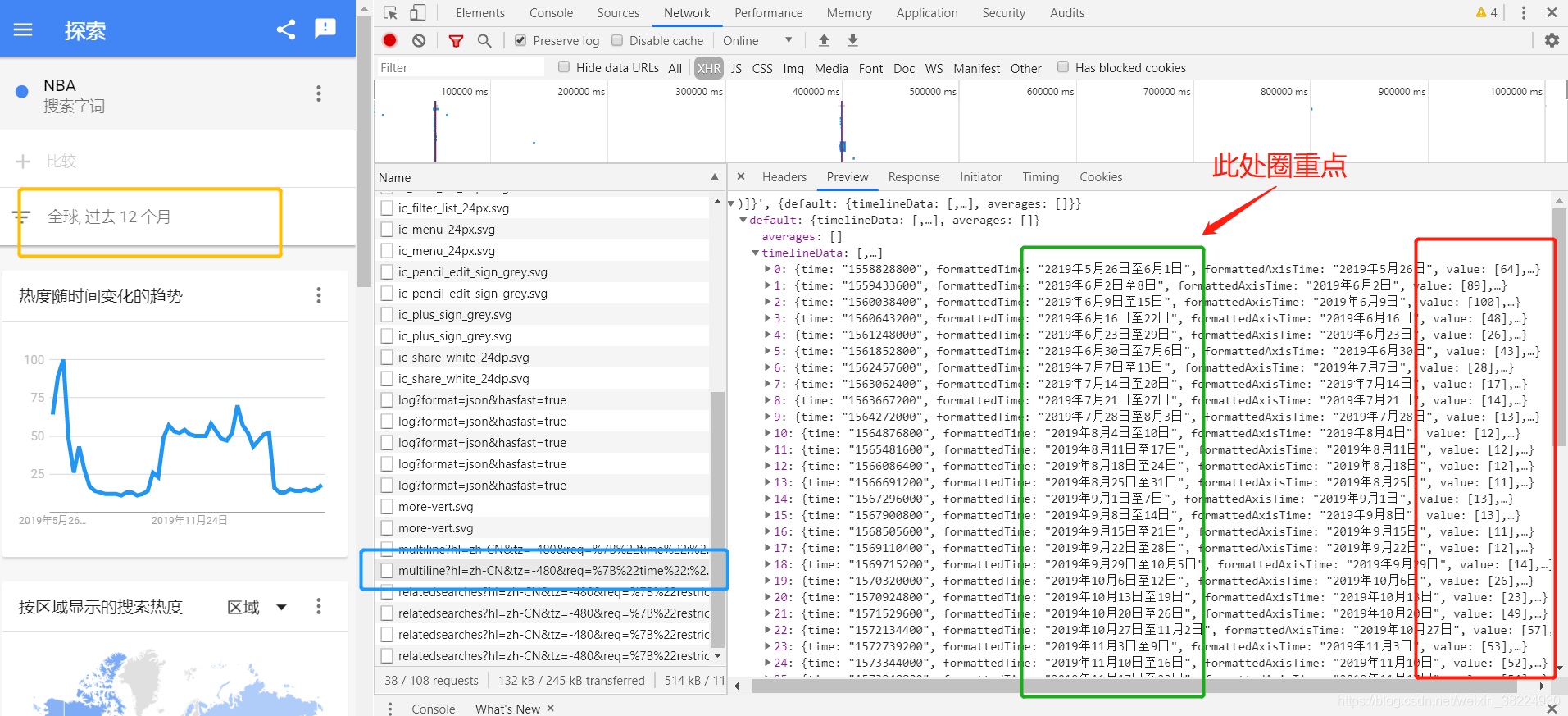
寻找token参数
服务端生成了一个Token参数,它与req参数相对应,需要由服务端主机来提供。我推测可能存在一个特定的URL可以用来获取Token参数,于是我开始着手寻找。结果,我找到了一个全新的URL,它返回的结果中确实包含了Token参数。这感觉就像找到了一把开启数据获取之门的钥匙。
存储数据及展望
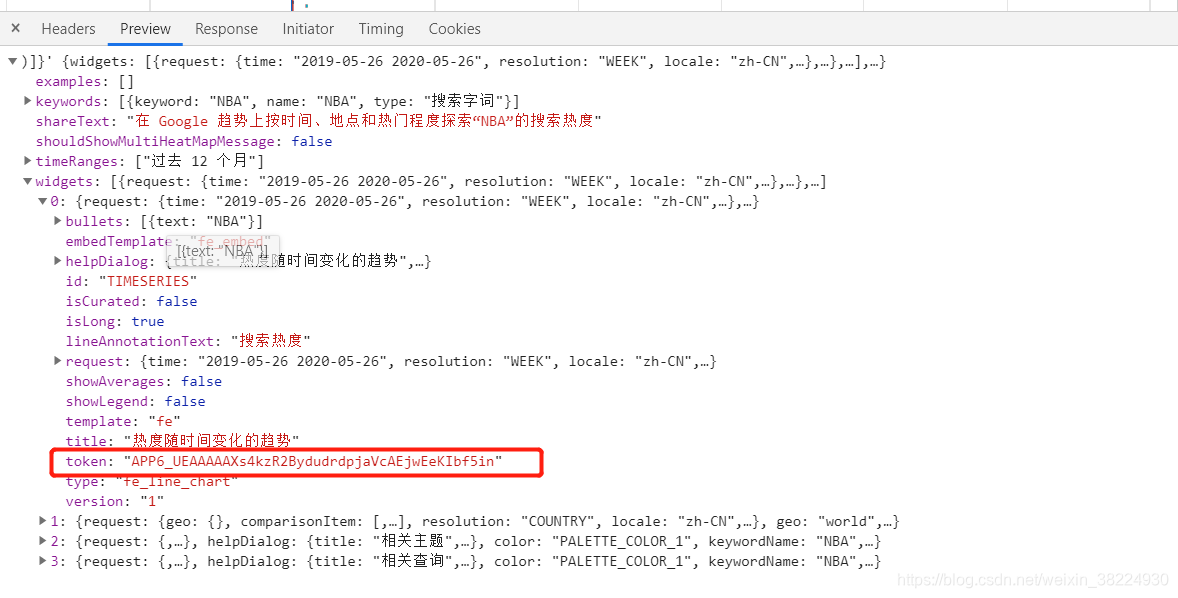
参数分析完毕,便开始收集并记录词汇出现频率。这一过程主要依赖特定模块,操作上只需按照现有功能执行。若要收集近半年的词汇频率,继续使用之前的方法是可行的;若需获取更长时间跨度的每日频率数据,则需新增一个时间循环模块。未来,我计划分享数据挖掘和机器学习的案例,以便大家共同学习和提升。
在使用Google Trend查询数据时,大家是否遇到过参数设置上的难题?若本文能给您带来帮助,还请您给予点赞,并分享给更多朋友。
发表回复